
Cognition Versus Programming: The Big Two
Why Is TDD Necessary ?

We humans suck at programming. We suck at reasoning. Any honest look at a sufficiently large and older piece of code will show you that our coding is atrocious in anything but the super small. Similarly, an honest look at politics and history over the years will tell you that our ability to use rationalization and the appearance of logic far outweighs our ability to actually logically reason over anything but trivial scales. Math and Physics are probably the best counter-examples.
There are two really strange results of all of this. First, somehow we make it all work anyway. Yup, that big honking piece of legacy COBOL might be an awful mess that's full of bugs, but it's been driving the bank's business for 40 years. Yup, scientists used to think they could look at the bumps on your head and tell what your personality was, but some of those same scientists helped push science into the modern era. We really suck at these things. We manage to make them work anyway.
Second, there is a unique crossover environment where our coding and thinking overlap, programming. It's common to hear teachers talk about "reasoning about the code". I used to say that the code "should read like a phone book, not a mystery novel". Hundreds of books have probably been written with the general thrust that we need to write better, more solid code, and that our code should be easy for others to reason about.
Because reasoning and programming sucks at anything but trivial scales, and because we programmers are in a unique spot to see this everyday, in this essay I'm going to draw a parallel between everyday human activity and programming. Whether you're talking politics with a friend online or trying to cure cancer in a laboratory, my thesis is that there are two main types of cognitive errors we make in our normal lives that also show up when we program. By comparing and contrasting these two types of errors both in our code and the real world, we might become both better programmers and better humans.
Observed Contextual Lock
This is the belief that through inspection and conversation, ie reading and discussion, the programmer has visibility into all of the smaller pieces needed to reason about the execution of this particular code block.
// Coding Language: C
// Purpose: Add two integers
int a=1;
int b=2;
int c=a+b;This is about as context-free as code comes. We have three variables: a,b, and c. Each variable is defined. None of them refer to anything else outside the programming language or code block.
Compare:
// Coding Language: C
// Purpose: Add two integers
int z=x+y;Looks about the same, doesn't it? But it's not. That's because x and y are not defined types. Sure they might be defined elsewhere, but they're not defined here. In both cases most folks would observe the code to be context-free. Everything's right here for us to see, right? We context-lock, thinking that whatever we're observing is the only things we need to observe. [1] We think, "You can drop that into a C compiler anywhere!" But these two examples are not the same. Context lock begins happening the minute you move in complexity beyond our first example. Hell, even if we knew x and y were ints, how do we know this operation is not going to overflow? Only by looking at other context, that's how.
It's amazing that context-locking is so natural that we don't see ourselves doing it. For example:
// Coding Langauge: Java
// Purpose: Demo Certain ArrayList features
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class CollectionsAddAll {
public static void main(String a[]){
List<String> myList = new ArrayList<String>();
myList.add("my collection");
myList.add("is nice");
myList.add("right");
System.out.println("Initial list:"+myList);
Collections.addAll(myList, "perl","php");
System.out.println("After adding elements:"+myList);
String[] strArr = {".Net", "unix"};
Collections.addAll(myList, strArr);
System.out.println("After adding array:"+myList);
}
}Observed Context Lock is "If I see it, it's important. If I don't see it, it's not important." The only conclusion I can come to is that humans are hard-wired to look at one social context at a time. That wiring has come to us over eons of biological and social evolution.
The previous examples may seem trivial, even facile. We can move things up a notch.
// Coding Language: C++
// Purpose: Create A Container To Use Later
// this is mostly context-free
vector <int> scores (7);
// this is not
vector <char*> pets ("11");
// Why? char * is not "well behaved" enough for the user to be sure to
// know exactly what will happen under all of the standard vector
// operations, eg, what if it's a null pointer?Just as in the human example, we read over a bunch of things that make immediate sense. We know what sex is, for example. As C++ coders, we know what vectors are. Perhaps as we consume these comments we reflect on our experiences with each. Then something seemingly inconsequential like "char *", or the word "is" trips us up.
In fact, the more sophisticated you make these examples, the more it hurts when the mistakes eventually show up.
Observed Contextual Lock is: The belief that through inspection and conversation, ie reading and discussion, the programmer has visibility into all of the smaller pieces needed to reason about the execution of the code.
Perceived Abstraction Level
The belief by the programmer that by the use of variable, function, class, API, etc names, usually with friendly and easily-understood words embedded in them, the programmer is simultaneously using the general concept represented by those names such that the actual smaller pieces making up those symbols don't have to be considered, worried about, or interacted with. [2]
In our first two C examples, we had single-letter variables and only ints as a type. While "int" tells us a lot, x, y, and z doesn't tell us much at all. As coding became more complicated, it got easy to lose track of two things. First, what real-world thing does this symbol represent? Second, how's the computer storing it? What's it doing here in this code and what kinds of things can I do with it?
Usually the name was a reminder to the programmer about some future business value. The kind of thing was a reminder about what the capabilities and limitations were of the thing he was looking at. Back in the day, most of us started sticking the two together using something called "Hungarian Notation"
// Coding Language: C
// Purpose: start using something from somewhere
// else over in this particular code block
// Hungarian Notation provides a quick "naming mod" to help
// the programmer remember exactly what they've manipulating
// I'm going to get a zero-terminated string
// of the first dog catcher in a list
char* pszFirstDogCatcher=getTopDogCatcherForTheMonth();As computers got more powerful, everything got a lot more verbose. Hell, you can tell about everything you need from that function name "getTopDogCatcherForTheMonth()" Right?
Can you? Could you look at that function and know that it returns a string? I couldn't. What month? What list of dog catchers? What qualifies as a dog catcher? How do they get on this list? What criteria is used to sort it? Variable names and abstractions allowed simple symbols to represent much more complex symbols, much the same as "int" represented a lot of electronics happening in the CPU. [3]
; Programming Language Lisp
; Purpose demo a hello world program using macros
; taken from https://www.geeksforgeeks.org/macros-in-lisp/
(defmacro sayHello ()
; This statement will be executed whenever
; we use the macro sayHello
(write-line "Hello everyone")
)
; Using macro sayHello
(sayHello)
(write-line "GfG")
(sayHello)
(terpri)
(defmacro greet (name)
; This statement will be executed whenever
; we use the macro greet
; substituting name with the parameter value
(format t "Welcome ~S ~%" name)
)
; Calling macro square with parameter strings
(greet "GfG audience")
(greet "Awesome people")
(terpri)
(defmacro sumup (a b)
; This line will be executed whenever
; we use the macro sum
; with two integer parameters
(format t "~D + ~D : ~D" a b (+ a b))
)
; Calling macro sumup with parameters 7 and 18
(sumup 7 18)
(terpri)
(defmacro square (num)
; This line will be executed
; whenever we use the macro square
; with the parameter name
(format t "Square of ~D is ~D " num (* num num))
)
; Calling macro square with parameter 5
(square 5)
(terpri)Sometimes programmers tell bad jokes in code. One of them is when somebody uses a preprocessor macro and defines true for false and vice-versa. Much hilarity ensues. You can also have fun in languages like C++ by taking the int type and overriding the (+) operation. Then when somebody types in "a+b", suddenly your computer is phoning Bora Bora and asking to have a pizza delivered.
We're a funny bunch. We amuse ourselves with our own cognitive limitations.
In our first example, if "int" is hard-wired into the CPU, it's an abstraction, but one we can be sure of. No matter what, we're not going to be taking apart our CPU to figure out how "int" works or all of the thousands of small parts the word "int" might represent. Compare that to this C# code
Coding Language: C#
Puprpose: Set up threads to async handle JSON data requests
private async Task<T> Post<T, TRequest>(string path, TRequest data)
where TRequest : Request
{
var authPath = GetAuthenticatedPath(path);
var response = await _client.PostAsJsonAsync<TRequest>(authPath, data);
return response;
}The crazy thing about this example is that while I can read the code almost like a phone book, and I can even grasp at about a 90% level of certainty what's going on, every one of these symbols represents an abstraction that I'm likely to have to worry about if I keep this code around for the next ten years. That's because the underlying library, implementation, references, dependencies, and so forth are always changing but my use of them is not. Even if the direct language spec didn't change, there's at least a dozen dependencies here that are likely to.
A common problem with modern event/message massive queuing is dealing with situations where multiple types of messages are needed to be received, perhaps in a certain order or not, for an important business event to take place.
Don Syme and Tomas Petricek use the simple example of a UI interface where some things depend on others happening:
"...Let’s say that we want to reset the counter by pressing theEsckey. In practice, this means that we need to wait for either Clickevent orKeyDownevent that carries theEsckey code as a value. Unfortunately, this cannot be written directly using existing constructs. Usinglet!we can wait for multiple events only sequentially, but not in parallel. What do we do about this? One approach is to use a combinator library..."
The details and implications of all of this are outside the scope of this essay. Here's an example they use.
// Coding Language: F#
// Purpose: Reset A Counter When ESC Is Pressed
let rec counter n = event {
match! btn.Click, win.KeyDown with
| !_, _ -> let! _ = Event.sleep 1000
return n + 1
return! counter (n + 1)
| _, !Esc -> return! counter 0 }You might think that pressing an ESC key is about as simple of a problem as there is, and it is, but even in this tiny business domain we run into all sorts of really complicated concepts that most of us have never thought of before. Just like with cognitive problems in our human world, in our coding world most of the time we're okay with not knowing everything and having it mostly work, but sometimes it breaks.
Instead of a simple UI and a user pressing the ESC key, imagine a distributed cloud system where a receiver might be waiting on a dozen different kinds of things happening, all with rules around whether those events need to be simultaneous, parallel, or sequential. Keep in mind that we've already admitted that we got lost with the simple ESC example. [4]
Now imagine all of that data being versioned. Imagine each version of each piece of that data depending on other types, also versioned. For each of those programmers responsible for each of those messages, everything is fine. Unit and behavioral tests run green.
Let's take that concept and apply it to people.
Imagine a typical human conversation with four people involved. This conversation might consist of 1,000 or so words and an uncountable amount of non-verbal messages going back and forth. For each person, each concept introduced has a history, a set of versions that it's gone through, and cross-checks with other concepts the person uses to make it make sense to the

Why did programmers start using Hungarian Prefix Notation as programming took off? Because the only way humans can deal with not being made out of computers is to abstract concepts and deal with the abstractions as abstractions, not the underlying concepts themselves. Hungarian Notation wasn't just a coding style, it was a cognitive hack. We have to abstract or we can't accomplish anything useful at all. [5]
True abstractions converts concepts into commodities for all consumers of that abstraction. CPUs abstract electronics for C programmers. A C programmer treats all CPUs of a certain kind as fungible and interchangeable. They'll never worry about versions, branding, patches, or whatnot. Serverless, cloud computing abstracts the idea of a PC to people who use only standardized coding languages. They'll never have to worry about exactly which virtual PC is running their program, if any.
Of course, this isn't an iron-clad rule. It's a heuristic. To the degree that it's true, you have a useful abstracton. 1-in-1000 events happen, like the SPECTRE vulnerability on Intel CPUs in the late 2010s. But if you have a true abstraction, you measure your value to consumers in statistics: uptime, oddball events that require their work, cycle speed, average warm-up, and so on. There's a good reason that the only metric to use with true abstraction is statistics! If you become concerned about any particular detail of an abstraction, by definition it's no longer an abstraction.
Note: the C# async code above is not bad by any means. The Perceived Abstraction Level is not the actual abstraction level. That's a risk. Perceived Abstraction Level risk needs to be acknowledged and managed. We naturally tend not to do so.
There's a myth that the amount of human words we add directly to the code actually increases it's ability to be used by the programmer. Clarity, terseness, unambiguousness ... these are all great to have in an essay but can easily lead real humans astray doing their day-to-day lives.
Take this example of two detectives doing a very complicated job using only one word, "f***" (Warning: contains lots of f-bombs, nudity, and dead people)
Why Do These Things Keep Happening?
Math/programming and human language/reasoning both use symbols to represent things. Math and programming have some hard and firm rules about which symbols can be used, when they can be used, and so forth. Human language, as it's actually done, has no rules at all. Human language not only uses written symbols, it includes body language, gestures, music, and so forth. It's really much more of a performance art, like a comedy improv, than just writing and manipulating symbols. Writing is just the best way we have of making human communication permanent. [6]
Both of these things involve things we can write down. Because of this, when we think of "word" or "sentence", we think of a piece of written text. In actuality, throughout 99% of human history, and for most folks even today, language is something one actively participates in through listening, watching,, movement, and talking. It's a social dance we constantly perform.
If I say that my father's hair was "fine" ... you would have to take a careful look at the other parts of my communication. Was I being sarcastic? Am I approving of his hairstyle? Does he even have hair? Is his hair fine as opposed to coarse? And so the various meanings go on and on. If, however, I say that "X=7"? Whatever it means in the current coding/mathematical environment I'm using today, it'll mean the exact same thing a thousand years from now. No careful observation needed. No humans required.
Programming is where these two world collide. We can easily write things in code that look just like sentences. We like to make our programs look like human language, as if the original programmer is in the room talking to us. They are not, at least in the way humans process language.
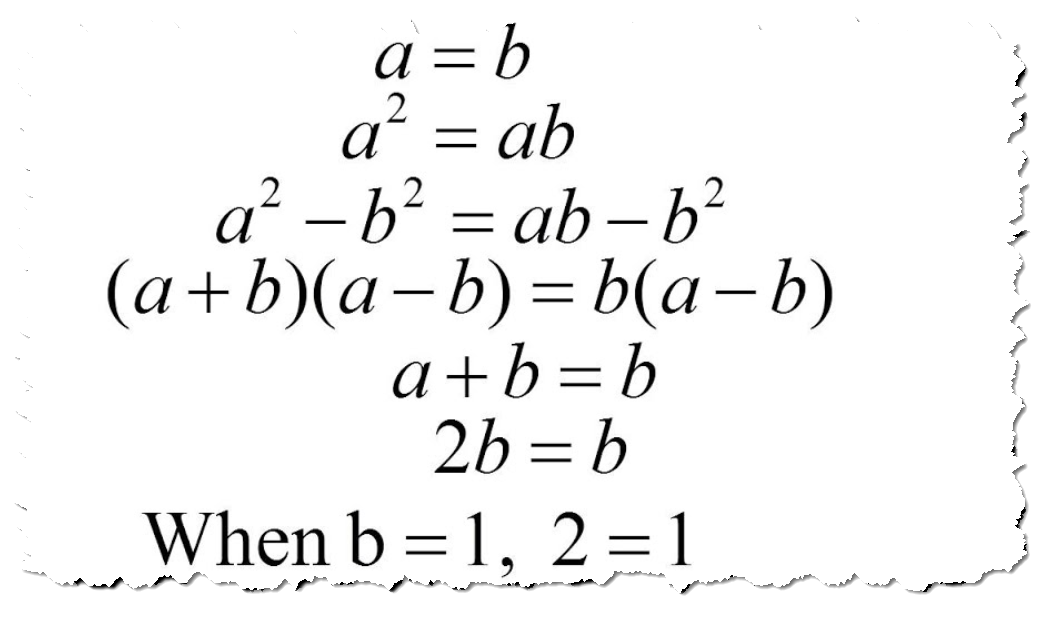
Likewise, we like to use human language as if we are setting up a geometric proof. It's easy. We can easily use human language to communicate statements that seem logical or rational. "All humans are mortal. Socrates is a human. Therefore Socrates is a mortal"
The difference is that in programming, eventually the code crashes. We don't understand our programs the way we think we do. Our programs do things we didn't plan on. Human communication, since it is an ongoing performance art, never crashes. Another way of looking at it is that human communication is always wrong but always evolving to be "right enough" to get the current job done. It is a completely different universe from coding. When we created/discovered math, we came up with something that looks human but is not. Over the centuries, the math folks were working far too slowly to have their systems crash as fast as our systems do. (Lucky them!) The human communication system isn't even playing in the same arena, as much as we'd like to think otherwise.
What Can We Do To Mitigate The Risk?
Since programming is where the two worlds collide, we can use techniques we've picked up thinking about complex code to reason better about human things. There are principles that hold true for both good coding and good reasoning.
If coding is where these two worlds collide, where specifically, does this happen? The answer is easy for anybody who's coded to solve problems for a living: testing. Acceptance Test-Driven Development is about creating a business workflow to make sure your technology workflow is actually providing external value. It verifies that the business and the product are in line. Test-Driven Development is about creating a coding workflow to make sure the complete totality of your code aligns with your mental modal of what it's supposed to be doing. It verifies that your brain and the code are in line. ATDD looks at everything from the outside, top-down. TDD looks at everything from the inside, bottom-up.
ATDD is the human language to code side. TDD is the code to human language side.
#include<stdio.h>
char *c[] = { "ENTER", "NEW", "POINT", "FIRST" };
char **cp[] = { c+3, c+2, c+1, c };
char ***cpp = cp;
main()
{
printf("%s", **++cpp);
printf("%s ", *--*++cpp+3);
printf("%s", *cpp[-2]+3);
printf("%s\n", cpp[-1][-1]+1);
return 0;
}
It all comes together in the practice of testing.
Beware of Context Lock
Never think that because you're looking at piece of code that you're looking at all that's important to you.
Define Abstractions Through Executable Tests
You can't say that something represents something else unless you have agreed-upon executable tests that validate that representation. Otherwise it's just words.
Reduce To The Simplest Proposition Possible
In TDD, we're always looking for the smallest possible thing we can test, starting with zero, i.e., "does it compile". In life, we start with billions of concepts, but when we're talking with folks about a problem, we're looking for the same thing: what's the simplest statement we can agree on but predict different answers because, perhaps, we're using slightly different definitions?
These are called Pivot Questions. They're the human-language version of TDD.
It's interesting to note that much of what the Computer Science industry considers good programming practices, things like SOLID, the Unix Philosophy, ATDD, TDD, Kelly's Skunk Works rules, and so forth? They're just specific instantiations of these generic principles, only for technology creation. [7]
out.
P.S. I apologize for the "What to do" part being so short, but this is a multipart discussion which builds on itself. If you understand and agree with the argument so far, you understand "Why TDD" and we're ready to move on to the next part. DM
- Basiat called this the "seen and the unseen". Here's an introductory essay I found randomly online.
- You might think of the Perceived Abstraction Level problem as being the Conceptual Lock problem covered up with a name. We read the name and assume all of the context needed has been provided
- Observed Context Lock is a programming problem. The underlying system may be rock solid, i.e. provable code. We know what each little symbol is and what it can do. We can trace any piece at understand at length exactly how things relate to one another. We just are incapable of understanding how everything might be connected to one another at any one point in time. Perceived Abstraction Level is a language problem. We are told what something is by way of abstraction or label, but there's no social context or history to refer to to verify whatever assumptions we make about what exactly that means. Whatever it is, it's really just what we guess it might be when we look at the label. (Type theory is where the two intersect, which is why type theory and testing go hand-in-hand so much in coding)
- Greg Young of EventStore brings up the fact that they solved this problem by limiting the kinds of things events could do and adding a theorem-prover on top of their engine. This is a very similar concept to Design By Contract, a technique used for many decades in various ways. Ada is the first example that comes to mind. There's a subtle problem here that's illustrative of the industry as a whole. We're talking about human cognition problems in society and while coding. Simply making the code impossible to crash doesn't increase our cognition of what it's doing. Here we have the old saw "It passes all the tests but doesn't do anything it's supposed to be doing". TDD is a tool that teaches design, that is, the fail-pass-refactor cycle teaches the programmer how the actual freaking code is working, something none of us really know. The fact that it works, if we don't understand it (or worse, think we understand it when we don't), doesn't help much when we're actually coding and maintaining unless we're learning while we're doing it.
- In my mind, Hungarian Notation was the first hint to a lot of smart people that our brains are not working like computers in some basic and unchangeable way. Massively-distributed versioned event systems, like above, should be the final straw for those who honestly look at the problem. There's simply no generalizing, gloss-over that helps us bullshit our way through it.Programming can help us realized the limitations of human communication. Likewise, human communication can help us realize the limitations of programming. The conversation goes both ways. That's a topic for another day, though.
- Socrates famously refused to write anything down. Turns out he was probably on to something.
- Covering the mapping here would be a huge list, and each item in that list might need a bit of explanation for the mapping to be clear. For purposes of this essay, we're just covering the mapping between these principles and TDD. This is the "why" of TDD



Comments ()