
How Do Software Projects End?
Nobody talks about how to end projects in our business. It's an odd thing.

Advent of Code 2022 is coming, and I've been playing around with some simple data sorting and slicing code in F# as a way to get back warm on my F# dev environment.
First odd thing I noticed: I had to turn off some of that crap I had installed on VS Code in order to make the IDE usable. There was so much "help" that I had trouble editing lines of code. Very weird. The IDE became so useful it was useless. (grin)
I started playing around with the environment as a result of reading this tweet by Urs Enzler
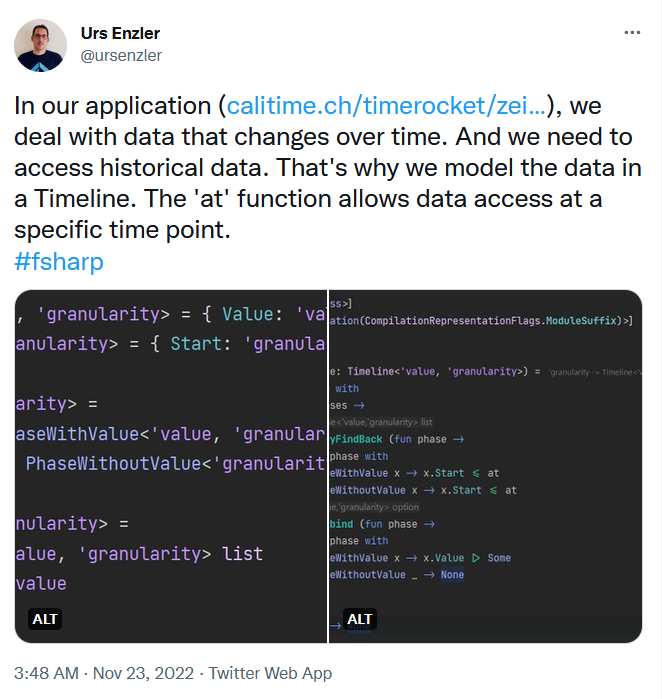
Ignoring the details of his tweet, mainly because I had little context to go on and am a very lazy person, the title reminded me of the chronological problem of relational databases. Since we tend to think of problems in terms of how one bunch of things relate to another, even if we don't use RDBMs, I thought it would be fun to kick around.
If you're not familiar with the problem, most of computing is based on some sort of hunk of stuff. Maybe it's an array, maybe it's an hashtable, maybe it's vector, maybe it's a collection. We've got what seems like a thousand names for "bag of stuff" (including bag, I believe). This should be a good indication that we use it a lot.
The problem is that we naturally think of how things relate to one another as a static concept: a customer has an account which has transactions. One bag of stuff has another bag of stuff which has yet another. In most cases this gets us far, far down the road to solving problems. Things get crazy when we realize that all of this stuff, including perhaps the names themselves, change over time, but we are supposed to make sense of it and solve problems anyway.
Folks who build databases have been dealing with this problem for a long, long time. In the last decade or so, there's even a new product called a "Time Series Database" If you're new to this problem, you can check out some nomenclature. The thing is that time series databases deal with certain things that are static and certain things that change. In the real world, everything is changing over time.
How Is Your Project Ending? Do You Know? Why Not?
There are approximately 42 kajillion people in the world that will tell you how to solve problems when programming. One of the reasons my IDE was so honked up was because I had went around clicking on various little gadgets that were supposed to solve some problem or the other.
Everybody seems to know everything yet the complexity mess remains. Interesting.
So instead of how to start, let's talk about how to stop coding. I can't remember ever hearing that discussed.
Let's say you're writing code to play poker or some other card game. It would be very typical in F# or another language to see some code like this:
type CardSuits = |Hearts|Diamonds|Spades|Clubs type CardRanks = |Ace|Two|Three|Four|Five|Six|Seven|Eight|Nine|Ten|Jack|Queen|King
The programmer thinks something like this: "We're playing cards. A typical deck of cards has four suits and 13 ranks. That's two lists of stuff. Each card is crossproduct between the lists."
type CardSuit = |Hearts|Diamonds|Spades|Clubs
let CardSuits =[Hearts;Diamonds;Spades;Clubs]
type CardRank = |Ace|Two|Three|Four|Five|Six|Seven|Eight|Nine|Ten|Jack|Queen|King
let CardRanks= [Ace;Two;Three;Four;Five;Six;Seven;Eight;Nine;Ten;Jack;Queen;King]
type PlayingCard = {Suit:CardSuit; Rank:CardRank}
let playingDeck=CardRanks|> List.collect (fun x -> CardSuits |> List.map (fun y-> x, y));;
(Aside: I almost immediately had to double my codebase, being forced to make a choice between DU and lists. I chose both.)
From here the programmer can go on and code the rest of the game: which hand beats which other hands, how to deal, and so forth.
But at some point, the game must end. At some point, the coding must end.
The Three Paths
DDD/CQRS
The latest hotness among the F# community looks like Domain-Driven Design, pehaps paired with Command Query Responsibility Segregation.
DDD is built on a simple yet beautiful concept: types for tests. In other words, some languages are powerful enough not to require unit tests. Tomas Petricek covers this in his "Why Type First Development Matters" Scott Wlaschin covers this in detail in his 2018 book "Domain Modeling Made Functional: Tackle Software Complexity with Domain-Driven Design and F#"

The idea is that I can construct a type system such that it is impossible for the program to be in an illegal state.
In programming every now and then you come across a thing of beauty, like generics or PaaS implementations. These are things you "kind of" knew that were possible but it is truly amazing to see happen. DDD is one of those things for me.
So you build up a type model that describes the world and the problem you're solving, make illegal states unrepsentable, then use a CQRS/parser-combinator pattern to ask the model to do things for you. It's mostly bulletproof. Yay!
type EventRecord =
{ EventID : Guid
Score : Int64
Stamp : DateTime
Headers : Headers
Payload : Object }
and Headers = (String * Object) list
and EventStream =
{ StreamID : Guid
Events : EventRecord list }
type private EventStore (store) =
member __.Store : Map = store
member E.ReadStream streamID =
E.Store |> Map.filter (fun sID _ -> sID = streamID)
|> Map.toList
|> List.map snd
|> List.sortBy (fun e -> e.Score)
(Some random F# code from several years back accessing Event Store. I didn't see a lot of F#/CQRS sample code, but I did see a few warnings about them not mixing well. I think this is bogus. The real problem is that because these are so different, you can't go half-assed on either one of them and expect them to work well together. To me that's a feature, not a bug.)
Monolith/Feature Mill
The bigger problem for coders is that the world doesn't stop for you. Today's rock-solid type architecture is tommorow's POS. This has nothing to do with programming. It's the world. We understand things differently over time. You can't freeze knowledge.
The traditional way of dealing with this is the ever-evolving monolith. Monliths are built on a simple yet beautiful concept: let's stick what we know into one spot and then agree on how it all works. We put what we know about the world and the problem we're solving into a large hunk of code. Since the world is constantly-changing, we're constantly honking around with that code. In 99.9%+ or more of the cases, this is not code that is bulletproof (by definition). So good clean coding practices and TDD are required if we're going to have any chance of keeping the lights on.
This kind of project has no end. Either we want new stuff or the world changes. In either case, we're opening up the codebase and doing stuff. Over time this almost always leads to cruft and needless complexity. (For reasons I won't go into here)
In the real world, commercial apps like this can only be replaced by another app. So your end state is either continual development or replacement.
Microservices/Onion/Composition
The Microservices/Onion/Composition pattern is built on a simple yet beautiful concept: life sucks; get over it. We build one behavior out at a time with zero dependencies on any other code. This behavior is tested before it's used anywhere. Inside the behavior itself we don't have tests. Instead we use DDD to make sure it is impossible for the program to be in an illegal state.
So you can think of it as ATDD-driven development or TDD at the microservices level. It's the same thing. In addition, many folks have talked about CQRS and True Microservices. It's too much to go into here.
Like DDD, true Microservices are dead and obsolete code the minute they're deployed, but it doesn't matter. Instead they're hot-swapped with new microservices when and only-when new external behavior is required. The "wiring" of the code, which data goes where, what happens in a race state, and so forth? It's handled outside the code. After all, these things are issues of how the code is put together (composition), not the code itself.
[] let main argv = printfn "Hello World from TaskBarrell!" argv |> processInput |> processData |> processOutput
(This is from a project I did several years ago. By going point-free and using a DDD strategy inside a true microservice, the code itself "goes way", ie is not part of the day-to-day worry of the programmer. Instead you end up assembling a DSL that becomes part of a larger enterprise language)
The problem here is horrendous (and I say that with this being my preferred endstate). You end up with a big hunk o loosely-coupled functions that you need to model, design, and stay ontop of. That's ops, and ops is always a pain, but really ops is part of the work anyway. This just makes it much more in your face as a programmer.
On the positive side, this path leads to small languages and DSL. They're a way out of the larger enterprise architecture software complexity trap. But that's for another day also.
Concluding
None of these are perfect. I could make good arguments for using any of these as valid endstates for a project.
What's not acceptable is writing any code without knowing where you plan on ending up. As I started in on just a few lines of F# above, I was immediately presented with a question: how did I want to maintain card and deck state in the code? I started down a DDD path with the intention of switching to monolith or microservices as I later decided what I wanted to make. I was modeling the problem, not writing code, and I was aware of that.
Nobody talks about how to end projects in our business. It's an odd thing.
P.S. The AI/ML guys are going after the time problem a different way. It'll be interesting to see how it turns out.


Comments ()