
Idea Assembly Part #473
Chaos, Cynefin, Complexity, Hexagonal Architecture, and Onions
Complexity is always the ultimate enemy when designing complex technology. The ultimate goal (in a commercial setting) is to build something people want that you can walk away from. If you're ever forced to return, and most of us are thousands of times, complexity is the thing that prevents doing a good job. It leads to bugs, cost/time overruns, unanticipated behavior, and so forth. Complex systems almost never become successful, but simple systems that are complex almost always end up as complex ones. Complexity destroys in the act of creating.
How Does That Thing Work?
Complex systems tend not only to be impossible to understand, they adapt their behavior as they are interacted with. For example, safety systems put on cloud architectures can actually lead to less-safe conditions. Economist Brian Arthur, along with others, came at the complexity idea when studying impenetrable economic systems, Complex Adaptive Systems (CAS) in the 1990s.
- They are composed of a multiplicity of things
- They have a dense web of causal connections between their components
- There is an interdependence of their components
- There is an openness to outside environments. They are not self-contained
- They show a high degree of synergy among their components
- They exhibit non-linear behavior
- Components change their behavior and relationship to others in order to optimize their own goals
Of course, any coder worth their salt will tell you that we solve the CAS problem in many ways: tiered architecture, OOP, Components, Clusters, Containers, and so forth. At the same time, and coder worth their salt will acknolwedge the sorry and ever-worsening state of technology: things take longer than they should to build, they end up with too many bgugs, and the relationship from end-value to knowledge-needed-to-maintain is non-linear. Looking at the industry as a whole, it is far more likely that we are lying to ourselves in various ways about the complexity problem than it is that we've actually solved it and everybody else is doing it the wrong way.
There is a danger here of ignoring the context. We tend to view attributes of complex systems in isolation, as if we could code just to "fix" one part of them, or as if systems only have one attribute of a CAS, as in the examples provided in the above diagram. Instead of looking at them as problems in need of a solution, which only leads to more CAS, we should look at this list as "tags", concepts we can associate in various ways to any system we build or examine.
How Can I Interact With Those Things?
CAS is all about looking at a thing from the outside-in. We are an intelligent creature looking at this blob of stuff. What's in there? The basic idea is that we can't poke at CAS with a stick and know ahead-of-time exactly how it's going to respond. Likewise, there are times we have to flip the script and look at a thing from the inside-out. We are an intelligent creature looking at bunches of blobs of stuff. Which of them are complex, which of them are simple, and so on? A rock is simple, we don't need to worry about how a rock interacts with us. A bear is not. We might not want to poke the bear with a stick!
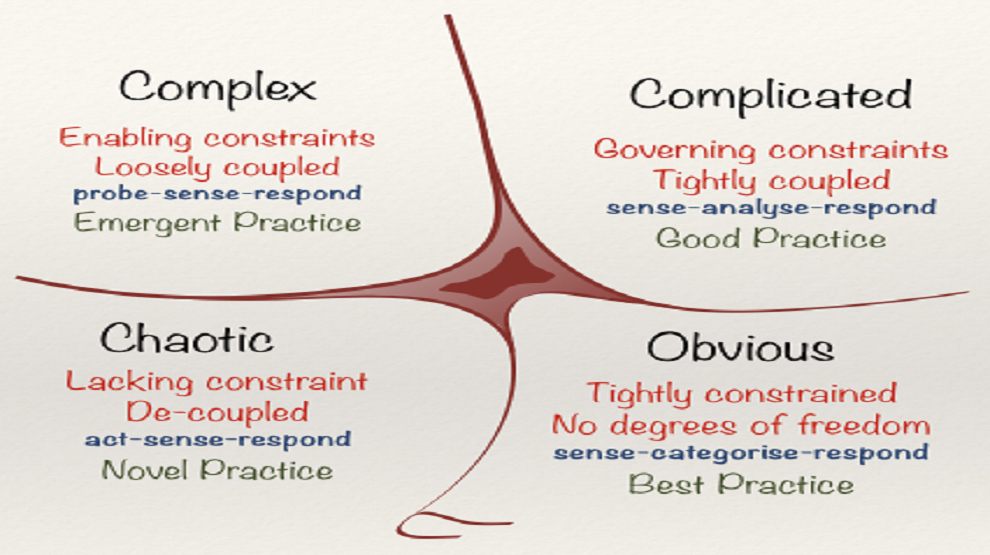
Trying to identify the various natures of the blobs outside of us is the goal in Cynefin. Cynefin characterizes our world into four categories
- Simple (Clear)
- Complicated
- Complex
- Chaotic
- Confusion (Added later)
Note that we've already overloaded the word "complex". It means one thing to the economists and another to the Cynefin folks. It can't be avoided. Also note that the first four categories of Cynefin are all about what the outside world is like. The goal is to identify the environment so that we can better interact with it. The last category, confusion, is more about how our inner world is operating. This is because Cynefin went from an epistemological framework to a management one as it evolved. In my mind Cynefin is best viewed as a "What kind of things am I working with so I can do a better job?" framework, not the thing it evolved into, which is much more like "How am I thinking about what the world is so I can straighten out my thoughts?" framework. That's the way I'm going to use it.
Is Naming Things Tough In Computer Science?
We've reached a point where we have a way of looking at things to figure out whether they can be coded easily or not (Cynefin). We also have a way of looking at the code itself to see whether or not it's easily to understand and maintain (the tags of a Complex Adaptive System)
It's time to look at architectures! Yay! First, one important axiom.
My simple, clear thing, in the aggregate, becomes your chaotic mess.
The assumption of both the Complex, Adaptive Systems (CAS) folks and the Cynefin folks is that we are dealing with things we can identify. There is an economy or part of an economy that's a CAS. There is a management situation we can drop into where understanding and applying Cynefin helps.
These are arbitrary distinctions! I could write an essay on just that fact, but here are two examples. My tiny piece of sand is a regular cube of silicon. As I am assembled into a dump truck load of sand it is also a simple system. But drop a grain of sand piece-by-piece into a pile? Suddenly it becomes chaotic. We can't tell exactly how the piece will fall, or when avalanches will occur in the sand pile. Likewise, managing my local pizza delivery restaurant might consist of working in simple, complicated, complex, and chaotic systems all at once. But the district manager sees a machine they have created where money goes in, a service is performed, more money comes out. It's all about perspective.
It turns out that what we name things and the boundaries we create mentally have a lot to do with how our eventual understanding works. Quantum mechanics is chaotic. How we understand it is complex. Using it to make a radio is complicated. Turning the radio on to listen to music is simple. When we listen to music, then, are we engaged with one simple system or a billion chaotic ones? The answer changes based on us, not the system itself, our perspective. Different definitions, boundaries, and how definitions relate to one another matters. (To put this in more fancier terms, our epistemological framework, our inner ontology, whether explicit or not, and our discrimination criteria for both of these things is both necessary and sufficient for performing analysis. It also varies from person-to-person, and much more is implicit than explicit)
Fortunately, we have a way of explicitly defining the names, boundaries, and rules of how things relate to one another: Type Theory. Type Theory is the basis of all computer science.
Our three pieces are now in-place. The first two describe the code I'm writing and the problem I'm solving. CAS describes the complexity of things we're looking at or trying to automate. If we want to maintain a piece of code, we want to stay as far away as possible from making a CAS in our codebase. Cynefin describes the world in which our code finds itself when it's trying to do something. When I write a piece of code, it should do one and only one thing every time. That's the Simple Domain in Cynefin terms. If my code does a bunch of things I don't understand but it works somehow the same every time? That's complicated. If it does a bunch of things I don't understand and sometimes it works and sometimes it doesn't? That's complex. If it works sometimes and sometimes it takes down the network and starts a fire? That's chaotic.
Programming is all about using a simple system, perhaps a single line of code, to come together with other simple systems (other lines of code), in order to make an overall simple system to solve a problem (which is also described in simple terms, tests). We cannot do any of this without defining things, defining how things join together, and creating rules about it all works. That's Type Theory. (Not that this has nothing to do at all with whether or not you using strong typing or not. At some point everything is ruled by Type Theory in programming, even if we have to dive down into the hardware to see it)
When these three things come together, we call it architecture
Architecture
As noted earlier, we keep fooling ourselves into thinking we're working with simple systems when in fact we're creating chaos. If I create a class called "SchoolBus" and send it to you, you might be able to use it in your code as if it were a real school bus, adding kids, driving to houses, dropping off kids, and so forth. But it's not a real school bus, and when that abstraction fails, we call it "leaky". Of course, all abstractions are leaky. The code is never going to be the actual bus. But that's true with any piece of code anywhere. The "int" in your C code isn't a real integer; it's a bunch of bits somewhere.
The reason "int" works every time whereas "SchoolBus" is likely to fail for the consuming coder is due to coupling. "Int" is highly-coupled to the real-world idea of an integer. You are unlikely to come up with a way of using it that doesn't match for all other integers that could ever be. It's about as tightly-coupled as you can get. "SchoolBus", on the other hand, is very loosely-coupled to reality. It's just a few things somebody threw together to do things for them that they thought Schoolbuses did. Another coder, even another coder solving the exact same problem, would come up with different things. Or name them differently. Or even eliminate the name "SchoolBus" altogether and look at the same problem using different names.
The real world is quite loosely-coupled. You can't create a "SchoolBus" type that is as tightly-coupled to (an) actual Schoolbus(es) at all. You can't even get close. The reason we keep creating messes when delivering technology is that we keep fooling ourselves the actual coupling we're using. On one hand, we want to think things are much more highly-coupled than they actually are. "Here's your SchoolBus class. I've made a place to put everything about schoolbuses!" On the other hand, we want to think things are much more loosely-coupled than they are. "Here's this function I haven't tested. I feel quite sure that I can drop it in this piece of code and it'll work just the way I imagine it will."
Coupling is neither good nor bad. We just have to have an honest understanding of how much we're using. Type theory is the way we create loose or tight coupling (remember, this is not about what kind of language you like coding in), so we're going to have to use Type Theory to give us a rock-solid view of how much we're actually coupling in our code if we want to stand a chance of creating technology that does something useful that we can walk-away from.
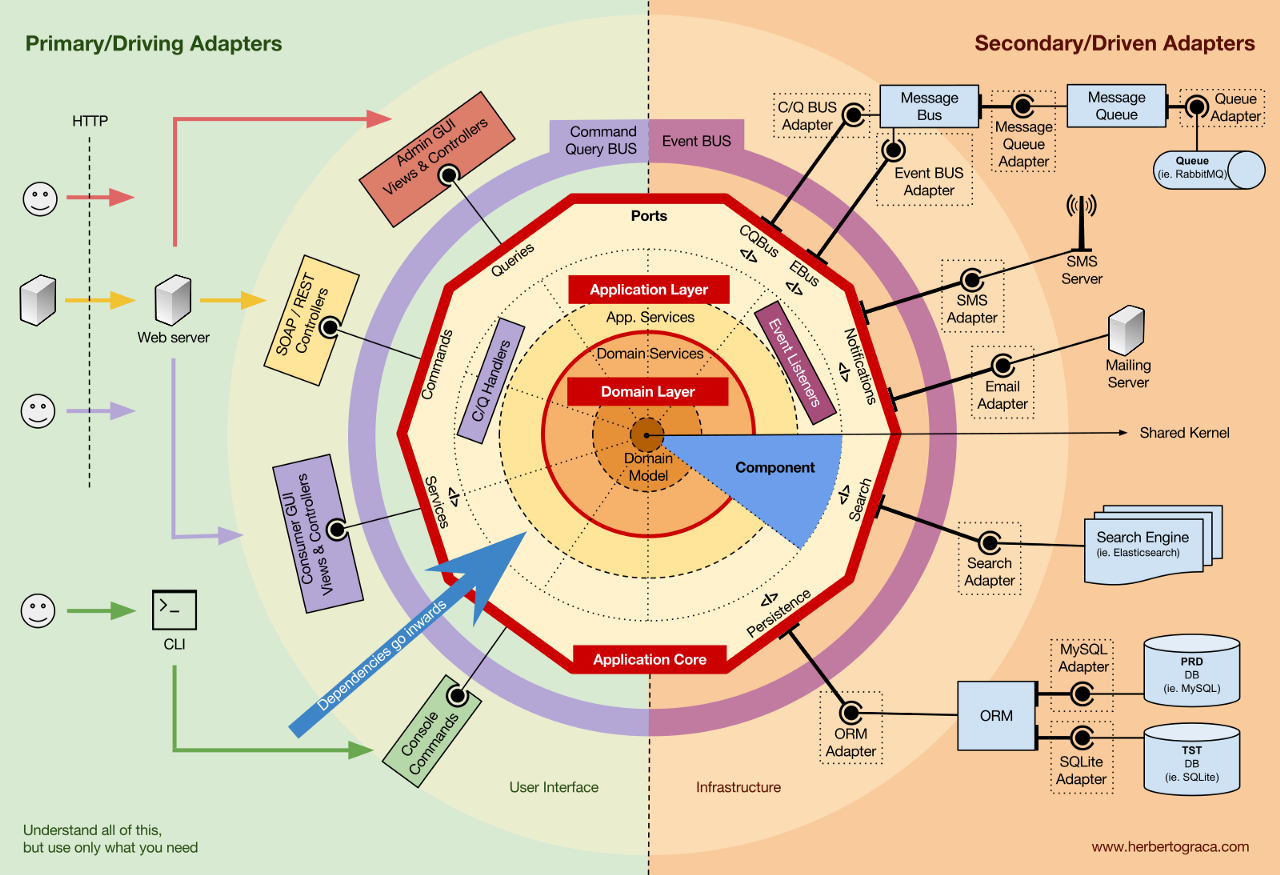
When we start talking about architecture, or the joining of our three concepts (CAS, Cynefin, and Type Theory), we instantly run into a bunch of nice, smart people who are coupling a bunch of bullshit up and then pretending it's not coupled. We have met the enemy and he is us.
Hexagonal Architecture, for instance, consists of four parts. Why do they call it a Hexagonal Architecture when there are only four parts? Long story. The general idea, I think, is a good one: there's your code, there's stuff outside your code, you get to that stuff using adapters. There are four different types of adapters: Business Events, Notification, Persistence, Administration.
But wait. There's more.

We've already coupled stuff up. These four types of adapters are types of adapters, ie, we are making rules, names, and boundaries before we even start talking about solving any kind of problem. The idea is something like "Hey, we know that we're always going to have these four kinds of things. Let's just sort them out now before we start"
Yeah no. Once again, there's nothing wrong with coupling! There's everything wrong with lying to ourselves about it. We should go as far as possible coupling only to the problem we want to solve and nothing else. We should be forced at the last responsible moment to add any other coupling that is required to the outside world and not part of solving our business problem.
I can hear several brains exploding as I type this. How could that even be possible? Don't you have to write code on a computer? Isn't that tightly-coupled to the hardware? Aren't you going to have to live on a network? Isn't that also tightly-coupled? Then why shouldn't you start talking about adapters as soon (or before) you start coding?
Once again, yeah no. Our code is coupled to the real-world concept of "integer" in a way that's not even close to the way our code is coupled to the concept of "network", as any network administrator can tell you. 1+1=2 is a completely-different kind of thing than using an URI to make a HTTP2 call, although they both can look like they are the same in the code itself (See: fooling ourselves)
After we spend a few hours with millions of examples of fooling ourselves, eventually our nice, smart, kind folks will ask something like this: "Well crap, how can you have any architecture at all, since at some point your code has to couple in some way to the outside world?"

The Onion
The Onion Architecture is based on just this notion: we have to couple simple things (our lines of code) in ways to make other simple things that deliver value we can walk away from (apps or microservices). This coupling should be as tight and simple as we can possibly make it. Once we've done that, and only then, we can begin coupling to other things in the world, things like discs, databases, operating systems, networks, other pieces of code. Cynefin gives us the layers, and CAS gives us the code smells we need to organize things inside those layers. Type theory describes the solution, whether we use actual things we call "types" in our code or not.
In other words: my simplicity, at scale, is somebody else's chaos. It is a reality that cannot be avoided. Therefore, whatever our solution ends up being, in the mind of anybody else besides us, it is a thing like "integer" that we can (and should) tightly-couple to the way we solve problems. They use bits and pieces of all of this to assemble. This shift from inside-my-solution to I'm-joining-a-bunch-of-stuff-up is the basis of all computer architecture, whether we acknowledge that or not.
Let's take a look:
- Chaos is the outside of the onion. Nothing matters to us here. We just have to be able to run our code
- Complex is the first inner layer of the onion. Things come to us from time-to-time. Perhaps we are open to receive text streams, perhaps we receive events we've subscribed to from and event queue. These things are beyond our ken to understand, but we can tell whether or not we got them or not. The first inner layer of the onion is all about "Did we get that stuff we wanted?" For each kind of stuff it's a yes/no answer. If there are any "nos" we just stop running and wait for some more stuff. There is no failure here; we either have the stuff we need or not.
- Complicated is the middle layer. We have the kinds of stuff we wanted! Yay! Like the first layer, there's only one question to ask here as well "Does the stuff we have make sense to solve the problem we have?" Once again, the only answers are yes and no. Once again, if it's a "no", we just stop running and start waiting again. There is no failure in this system.
One might ask: "Isn't 'no' a failure?" No, it is not a failure! If the stuff we have is supposed to solve the problem but doesn't, then either somebody else thinks they're giving us the things we need but they are not, or we don't understand the things we need ourselves.
This is an important point. Both of these situations are business problems, not coding problems. Somebody, some real person, needs to make a decision that we can then code. You can't (and shouldn't) hide this problem with abstractions or whatnot. There's an important people-problem here, and important people need to solve it. This is the basis of the concept of the app talking back to the business. Coding is a two-way street. If the code isn't telling us stuff we need to go figure out then we're coding the wrong way. - Simple is the core layer. This is where everybody wants to live in their mind when they talk and think about coding. I have these types and names for things in front of me in the IDE that I understand and that I know how to manipulate. As I manipulate them, the program responds in the ways I expected. It is a beautiful world. If we use the Onion Architecture we can live there. Otherwise we cannot. We can't pretend-away our coupling. We must acknowledge and deal with it.
- Libraries (bonus layer). Just like the Cynefin folks added a "bonus" layer once they started subtly shifting from talking reality to managing, the Onion Architecture adds a layer as we subtly shift from talking solving-a-particular-problem and language design. Things come together in ways that will always be the same and that others can use without any fear of unwanted side-effects. Here we see a true DRY, or Don't Repeat Yourself. They only occur in the Core Layer, and they're only related to the business or the general type of work being done. If it's about the generic work, we're factoring out to add to our programming language. If it's about the business, then we're creating the beginnings of a Domain-Specific Language, or DSL. DSLs are about making a programming language, not about solving a particular problem. How to assemble and test DSLs is a fun topic outside the scope of this essay.

Calling BS
There is one final objection that deserves mention: aren't we just shoving a bunch of problems off to somebody else? Yes, we are, but those problems are the problems of those folks anyway, not us.
Remember: boundaries matter. As coders, we are not solving any sort of problem our business person has in a way that can run anywhere on any OS. We have to scope down. But hell! We don't scope down by starting to specify particular OSs, libraries, frameworks, databases, and so on! We're freaking coupling the wrong way! These are things that change all of the time. It'd be like creating an "int" to use in our code that sometimes worked like an integer, sometimes like a network adapter, sometimes like a distributed datastore. Never couple the thing the programmer has to use to anything but the exact thing the programmer thinks they are using. Only the Onion Architecture does this. Every other architectural pattern does not, and there is a saying about camels: Once the camel has his nose under the edge of the tent, the camel is in the tent. Once you say something like "It's okay to couple here but not there" you have effectively coupled everywhere that other thing couples. And starting a project explicitly coupling to an entire group of things that might generically be called something like "datastore". It's insanity. Don't do it. You don't have to. Use the Onion.
If you use the Onion Architecture, you and your friends will create little chunks of code that do one and only one thing and are simple to reason about from the outside. Each piece, like a simple line of code inside a computer program, exists in the Simple domain in Cynefin.
Many well-meaning projects get this far and then fail. That's a tremendously sad thing, especially since they have all of the pieces they need to be happy. You see, if you solve business problems using the Onion Architecture, you end up with little pieces you can then use to solve organizational problems using those same pieces! Win! It's just a bigger onion at scale, and it uses the exact same layers from Cynefin and the exact same code smells from CAS as your onion did. Your app is my function.
It's turtles all the way down. Before you get too happy, though, you must understand that each little onion piece, ie each little app/microservice, corresponds to a line of code. Putting all of those little onion pieces into a larger onion involves not only assembling the little pieces but defining semantics for a programming language, perhaps even an IDE. Here's the bad news: You're creating an entirely new programming language, one of your own making, only based around your organization, not some generic programming language.
This means that architecture and programming language design are actually the same thing, just at different levels. When you start programming in C, for instance, we give you programming language. If you're really good at solving a bunch of the same kinds of problems, you'll end up building a DSL just for your kinds of problems. If those problems are generic enough, that DSL will itself become a programming language, like C++. Then you start using C++ ....
It's all turtles. Here's your turtle. Time to get started!


Comments ()