
Outlines Of A Supercompiler In F#

Today I'll show you the outlines of the code needed to make a supercompiler work. Here's our set of microservices: (supercompilers were introduced in my last essay)
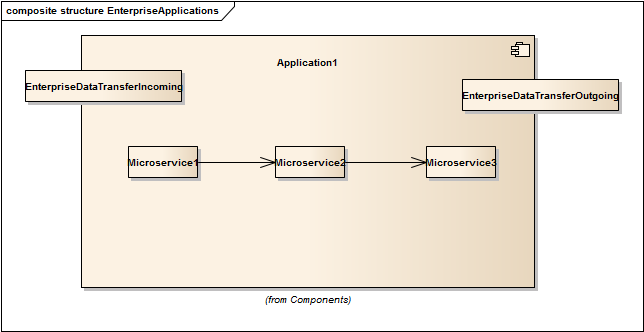
Note that we don't care about Enterprise Data. Maybe we get stuff from a message queue. Maybe we have web servers. Maybe there's a Data Lake. Wherever it's coming and going to, it will enter our application the same way everything moves around in our application: untyped streams of text data. You're welcome to change it to whatever you like, but don't freaking start adding types. We don't know what we're getting. We never do. It's true for the app. It's true for each microservice.
First thing we'll do is set up some types that everything inside our app will use. Because this is the first level of adding strong types (See the Incremental Strong Types essay), it'll have the minimum constraints possible.
namespace Application1
module AppTypes=
type UniversalAppDataStream = {
StreamName:string
DataLines:seq<string>
}
type UniversalConfigItems=seq<string>
type UniversalAppConfig=UniversalConfigItems
type App1Config=UniversalConfigItems
type App1Microservice1Config = {App1Config:UniversalAppConfig;Microservice1ConfigItems:UniversalConfigItems}
type App1Microservice2Config = {App1Config:UniversalAppConfig;Microservice2ConfigItems:UniversalConfigItems}
type App1Microservice3Config = {App1Config:UniversalAppConfig;Microservice3ConfigItems:UniversalConfigItems}
type App1Microservice1=App1Microservice1Config*UniversalAppDataStream->UniversalAppDataStream
type App1Microservice2=App1Microservice2Config*UniversalAppDataStream->UniversalAppDataStream
type App1Microservice3=App1Microservice3Config*UniversalAppDataStream->UniversalAppDataStream
type UniversalMicroserviceConfig=UniversalConfigItems
type GetAPPConfigFunction=UniversalMicroserviceConfigWe have a set of streams. Each has a name and each is a sequence of strings. If this sounds like "variant all the things!", stay tuned. We are incrementally locking this system down so that it is impossible for errors to occur. (Although it might be possible for a fully-working system to return something you asked for that you did not want)
Lines 13-15 takes our app config, adds a config for each microservice, and creates a strongly-typed config for that service. Note that I am taking apart the supercompiler. The average user would never see most of this.
Lines 17-19 says that each microservice gets a config and a set of data streams. It returns a set of data streams. All of these configs can either be passed in, set to a file, never used, provided by command-line parameters, and so forth. For now it's just a bunch of nothing. Lines 20 and 21 gives us a couple of defaults since for purposes of this demo we don't care about any of this.
Next we'll go to Microservice1. We have three files for this microservice: one for the types it uses, one for the microservice tests it must pass to provide a singular useful business function, and one for the doing the work itself. Note that while I'm using F# for clarity, none of this is language-specific. In fact, you could compile each piece using a completely different language for each one if you wanted. However it's 0/10, not recommended. Perhaps if you stuck with the dotnet family, it might work better?
Here's our Microservice1 Types file:
namespace Microservice1
open Application1.AppTypes
module Types=
type Microservice1Config=UniversalMicroserviceConfig
type GetConfigurationFunction=string[]->Microservice1Config
type GetIncomingStreamFunction=Microservice1Config->Microservice1Config*UniversalAppDataStream
// Dummy Type
type IncomingData=string
type ProcessIncomingDataFunction=Microservice1Config*UniversalAppDataStream->Microservice1Config*IncomingData
// Dummy type
type BusinessTypes=string
type TranslateIncomingDataToBusinessTypesFunction=Microservice1Config*IncomingData->Microservice1Config*BusinessTypes
type ValidatedBusinessDataType=string
type ValidateBusinessDataWithItselfFunction=Microservice1Config*BusinessTypes->Microservice1Config*ValidatedBusinessDataType
// more dummy types
type ProcessedBusinessData=string
type ProcessDataFunction=Microservice1Config*ValidatedBusinessDataType->Microservice1Config*ProcessedBusinessData
//dummy
type OutgoingStreams=string
type CreateOutgoingStreamsFromProcessedDataFunction=Microservice1Config*ProcessedBusinessData->Microservice1Config*OutgoingStreams
// dummy
type OutgoingStreamsReturnedToCaller=UniversalAppDataStream
type processOutgoingStreamsAndReturnToCallerFunction=Microservice1Config*OutgoingStreams->Microservice1Config*UniversalAppDataStream
// dummy
type OutgoingSreamsPersisted=int
type ProcessOutgoingStreamsToPersistenceLayerFunction=Microservice1Config*OutgoingStreamsReturnedToCaller->int
// dummy
type IncomingStreamsFromOS=UniversalAppDataStream
type RunInternallyFunction=string[]*IncomingStreamsFromOS->Microservice1Config*UniversalAppDataStream
While all of our functions simply pass around a dummy type (an empty string), in real life you'd start with untyped information and lock it down completely by the time you do the useful work. Remember this diagram from our Incremental Strong Typing discussion?
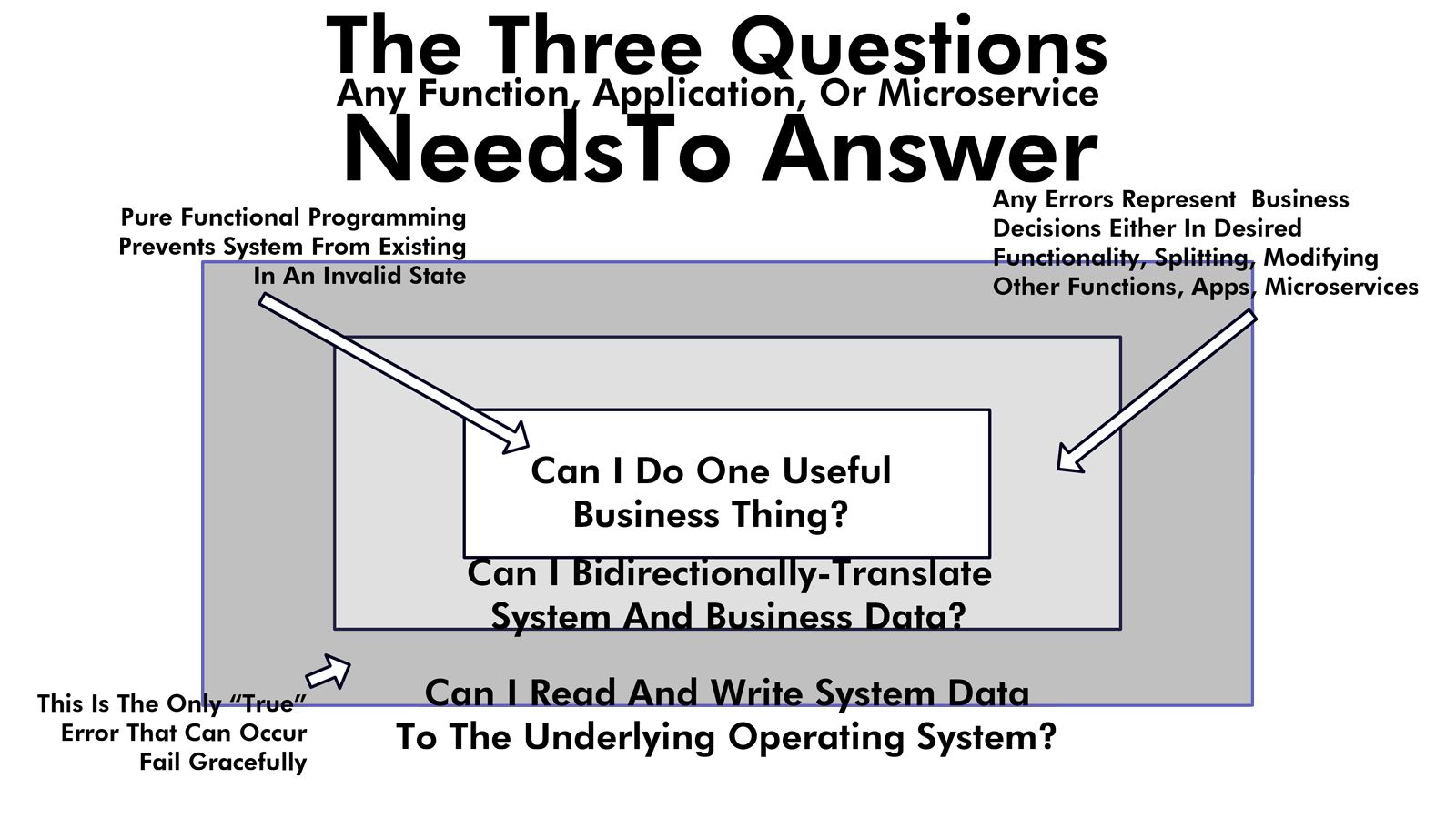
We have three layers to each microservice. Different layers require different kinds of coding and by slowly locking the system down to a Domain Driven Designed single business function, you force the business and developers to actually identify what's a single useful business function and what's either too big or too small.
Types are non-existent outside the box. Types inside the box control every aspect of program flow. This is true for both the microservices and the application overall. This is Event Storming by each unique event.
Now that we've locked-down what we're getting and what we're passing around, time to do the work. We do that in the Microservices1 dll.
namespace Microservice1
open Application1.AppTypes
open Microservice1.Types
module Main=
/// Take command-line args and whatever else and make a configuration for the app
let emptyAppDataTransfer:UniversalAppDataStream={
StreamName=""
DataLines=Seq.empty
}
let getAppconfig=emptyAppDataTransfer
let defaultApplication1Config=Seq.empty
let defaultApp1Microservice1Config =Seq.empty
let getMicroservice1Configuration (args:string[])=Seq.empty
let getAppConfig (args:string[])=Seq.empty
let getConfig:GetConfigurationFunction =
(fun (args:string[])->defaultApp1Microservice1Config)
let getIncomingStream:GetIncomingStreamFunction=
(fun (appConfig)->defaultApp1Microservice1Config,emptyAppDataTransfer)
let processIncomingData:ProcessIncomingDataFunction =
(fun (appConfig,incomingDataStream)->(appConfig,""))
let translateIncomingDataToBusinessData:TranslateIncomingDataToBusinessTypesFunction =
(fun (appConfig,incomingDataReceivedWithoutError)->(appConfig,""))
let validateBusinessDataWithItself:ValidateBusinessDataWithItselfFunction=
(fun (appConfig,businessStuff)->(appConfig,""))
let processBusinessData:ProcessDataFunction=
(fun (appConfig,validatedBusinessTypesToDoStuffWith)->(appConfig,""))
let createOutgoingStreams:CreateOutgoingStreamsFromProcessedDataFunction=
(fun (appConfig,processedBusinessData)->(appConfig,""))
let returnTransformedDataToCaller:processOutgoingStreamsAndReturnToCallerFunction=
(fun (appConfig,outgoingStreams)->
(appConfig,emptyAppDataTransfer)) // FROM OS WRITE DATA CALL
let persistTransformedData:ProcessOutgoingStreamsToPersistenceLayerFunction=
(fun (appConfig,outgoingStreams)->0) // FROM OS WRITE DATA CALL
/// the heart of the microservice:
/// a pure data functional transform
/// this is what's called from any
/// external supervisor/flow control
/// TLA+ app etc that wants to organize
/// the functionality
/// You can also just assemble these from
/// multiple microservices to create a monolith
let runInternally:RunInternallyFunction=
(fun (argv,incomingsStreamsFromOS)->
getConfig argv
|> getIncomingStream
|> processIncomingData
|> translateIncomingDataToBusinessData
|> validateBusinessDataWithItself
|> processBusinessData
|> createOutgoingStreams
|> returnTransformedDataToCaller)
/// app Flow
/// this is what happens from the command line
/// the data can come and go from wherever the
/// OS wants: files, message quques, etc
let run(argv, incomingStreamsFromOS:UniversalAppDataStream):int =
runInternally (argv,incomingStreamsFromOS)
|> persistTransformedData
[<EntryPoint>]
let main argv =
let defaultIncomingSteamsFromOS=emptyAppDataTransfer
run (argv,defaultIncomingSteamsFromOS)
There's a lot here even in stub form. Basically we take our types for this microservice and lock them into our functions that do the work. That's up through about line 44 or so. Lines 46-63 do the actual work. This runs point-free using composable functions. The application overall runs point free using composable microservices. It's turtles all the way down; that's the magic of it.
From lines 65 on through the end, we do a bit of housekeeping. This microservice can either run as a standalone exe (classic Unix-style command line app) or as a resource called by somebody else. We don't care where we're running. Some folks will just call us as if they were puppeteers. Some folks will pick up the command and play around on the command line. Some folks with interactively play with the app in the REPL. I understand Fable allows you to take each function and dynamically decide there it runs on the client on in a JavaScript function. Awesome. Way cool. It's all the same to us.
So how does that work? What's the dependency chain look like?
Here you go:
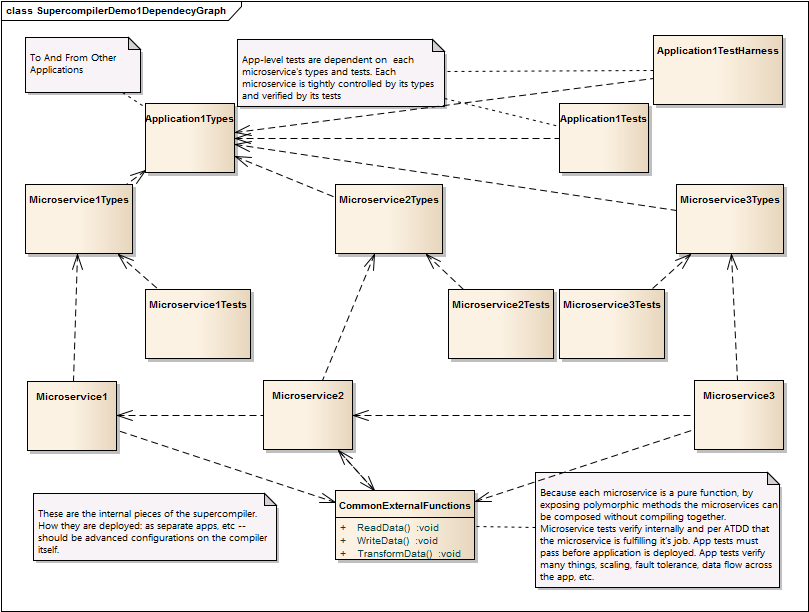
There are no cycles here, it's a DAG (Directed Acyclic Graph). You'll want to read the notes in this diagram.
Right now our test compilation units for each microservice (and for the app overall) are just stubbed out Expecto samples. You may want to pick up the code and start providing your own. I started playing around with it, but I ran out of time this morning. Basically, you want to be in a position in Application1Tests to do something like this:
open Expecto
open Expecto.Logging
open Expecto.Logging.Message
// DON'T DO THIS. IT INTRODUCES CYCLES
//YOUR APP-TYPE FILES ARE MEANT FOR ENTERPRISE CALLERS
//open Application1Types
open Microservice1.Types
open Microservice1.Main
open Microservice2.Types
open Microservice2.Main
open Microservice3.Types
open Microservice3.Main
module ApplicationTests=
let applicationTestInputData1 = emptyAppDataTransfer
let microservice1ProcessingApplicationTestData1 = emptyAppDataTransfer
let microservice2ProcessingMicroservice1FromTestAppInputData = emptyAppDataTransfer
let flowTests =
testList "Microservices Flow Test. SHOULD BE AUTOGEN BASED ON USER DIAGRAM?" [
test "Microservice1 runs with no input" {
let commandArgs=[||]
let res=Microservice1.Main.runInternally(commandArgs,emptyAppDataTransfer)
Expect.equal res (defaultApp1Microservice1Config, emptyAppDataTransfer) "No data in means no data out"
}
]
[<EntryPoint>]
let main args =
runTestsInAssemblyWithCLIArgs [] argsIn Expecto, our testing harness, tests are first class functions and can be composed as such. This is probably where the most work currently needs to be done. In addition to checking for cycles in the microservices, most all of this should be auto-generated. If microservice A outputs three hunks of data, that can be consumed by apps B, C, and D. They, in turn, might spawn more apps and so forth.
It's a hunka hunka burning pain in the ass to do by hand, but really it should never be done by hand. Joining up functions, allocating stack space, and so forth are problems that have all been solved a thousand times, once for each compiled language somebody made. In fact, you can take a high-level view of your average C compiler and just replicate it here. The microservices are the functions. The data is well-defined. There's some linking, sorting, perhaps a link file needs to be created and shared with other enterprise apps (or the IDEs of other developers currently working in this space). Whatever you do, it's well-trod territory. NOTE: the analogy isn't going to hold up forever, but it'll hold up well enough to meet the criteria outlines in my Honest Microservices essay.
I wrote two books on this stuff. You should buy them. 'Nuff said

Caveat Emptor
Like Scotty fixing the USS Constellation in order to save the Enterprise from the Doomsday machine, I've only spent one morning on this. I can tell you it compiles. (We do not have phasers working yet). The goal here was not to write an enterprise application full of microservices. I do that during my day job. The goal was simply to explain the supercompiler concept using a lot of code to see if folks respond to that better. I have no doubt that with a big enough hammer, all of this stuff will come together and work as a unit. Much profanity may happen, but there's nothing but the usual development BS to stop us from getting there.
It's a crap-ton of work. I'm a programmer. I don't like work. As big as something like this toy application is, framing up a development environment and starting to set up all of the test harnesses to verify that it's working is 2-4 orders of magnitude greater. Once again, no show stoppers, but there'll be a lot of little nits. Actually it'd be fun — if I had a team. And somebody paid me for it. I would also like a sports car.
A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over, beginning with a working simple system. – John Gall
I had to jump ahead. You should not be writing applications the old-fashioned way from the top down with lots of diagrams and code of this size. Successful complex systems always start as simple systems. Start with one microservice and none of this strong typing inside: you're supposed to add that stuff as you have conversations with your business partner. I had to fake it out as if we had been running for a few weeks or so in order to give you guys an idea of where this is going. Don't fake it.
There's really nothing new here. I'm just telling you that we've split things into so many thousands of small pieces that we can stop that; we can also join them back up into something simple. We should work a lot more on simple. Let's do more simple. Let's make coding fun for the new guys.
All of your favorites are still around, they're just in places you don't usually find them. We've got Dynamic Typing here. We've got Domain-Driven Design. We've got data flow. We've got class and component graphs. Everything we've been doing all along will still be useful and needed. The only thing that may give your head a spin is we don't focus on any of that stuff. Usually when you're leaning something like, I dunno, relational databases, everything revolves around relational databases: how to diagram them, how to secure them, how talk with users, how to Event Storm, and so on. On our journey, we've got too many pieces to dwell on any one area; we want people diving in and immediately making stuff people want. So we default a lot out. Technical careers should be about fun exploring.
We pick up these pieces and practices incrementally as our solution grows. So if you've got some thing you love a lot, say TDD, it's here. We got some tests. But the process flow and how the tests relate to the code may be quite different from what you're used to. I understand that this can drive some folks nuts. I get it.
I'm out of time today. Thanks for dropping by!
Go look at the code here


Comments ()