
Random Word Generator In Bash
A fun little bash function I wrote over dinner. It randomly chooses n-letter words based on the frequency that words occur in the language.
Like many people, I've been taken in by the current Wordle craze. If you're a coder, not only is it fun to play the game but it's fascinating to think of other games like Wordle you could write. I know of a bunch already. There's worlddle, where you guess the country's name. There's sweardle, which is wordle using only profanity. There's a wordle just for unix terms.
My favorite is quordle, where you play four wordle games simultaneously.
I don't have yet another version of Wordle I want to write, but I am interested in procedural data generation. How would you go about picking a 5-letter word, say where the words would occur with the same frequency as they do in the language?
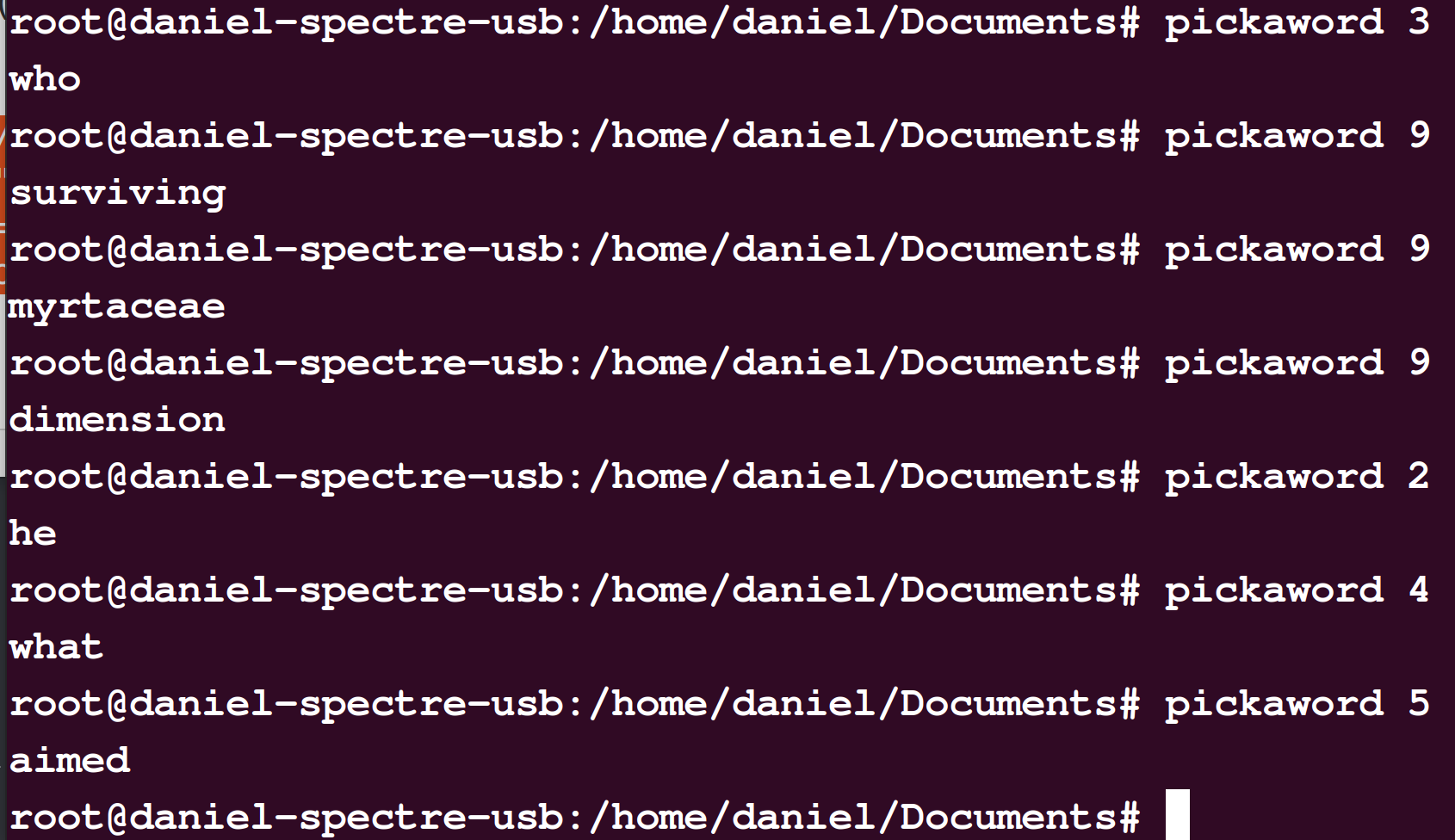
pickaword() { WORDFREQFILE=/home/mywords.txt;WORDLENGTH=$1; FREQSUM=$(awk -v wordlength="$WORDLENGTH" 'length($1) == wordlength {s+=$2}END{print s}' "$WORDFREQFILE"); CHOICE=$(shuf -i 0-$FREQSUM -n 1); awk -v wordlength="$WORDLENGTH" 'length($1) == wordlength {sum += $2; print $1, $2, sum} END {print sum}' "$WORDFREQFILE" | awk -v threshold="$CHOICE" '$3 < threshold' | tail -2 | head -1 | cut -f1 -d' '; }That's how you do it. Let's unpack this function and talk about how I wrote it.
First I needed a dictionary of English words and their frequency. Most modern OSs come with dictionaries, but they don't have frequency of occurrence information.
In some ways, this was the hardest part of the project. Lots of folks have data around words and word frequency, but the first dozen or so places I found online wanted to charge for it. Of course, I could generate a histogram by hand from some random corpus, but that seemed like a drastic measure.
Finally I found a word list here. It uses Wikipedia as it's corpus and contains hundreds of thousands of English words.
cat wordfreq.txt | shuf | head
darinn 3
ignatia 44
hudson-doris 3
banfield's 59
okcbiz 3
moigno 16
shallow-soil 4
zaviyani 3
aristobulos 5
roseblade 7It's got each word and a total number occurrences in the source corpus. The data slicing seemed fairly straightforward from here, but how much actual coding would I have to do? Did I need to get out my favorite IDE?
First, it's possible to start filtering. I needed to only look at five-letter words, or six-letter words. That was a fairly simple filter in awk.
awk 'length($1) == 9 {print $1}' wordfreq.txt | head
including
following
september
president
published
education
according
community
different
political
Now that I can filter by length, what now? My first instinct was to make a temp file. Perhaps I could make permanent files that were filtered. Maybe I could make several files, like 3-letter-words, 4-letter-words, and so forth.
In functional coding and scripting I am slowly learning to avoid naming things unless I'm going to be looking at that code later on. Ideally, you solve a problem and never come back to that code again. So I didn't take one file and make a bunch of smaller files, like I would have perhaps 15 years ago. Instead I strove towards a pipe-and-collapse strategy.
I have arrived at a strategy of piping the hell out of the problem and ignoring any error. I can do that since if you have errors with the computer guessing a random word, and these errors are important to you, then you shouldn't be using my code. Given this initial section of pipe. What are the words and frequencies for that word length? It wasn't enough just to have a "number of occurrences". I needed to get a ratio of how frequent that word appears. For that, I'd need both a running total along with a total of all of the n-letter words.
WORDLENGTH=5
FREQSUM=$(awk -v wordlength="$WORDLENGTH" 'length($1) == wordlength {s+=$2}END{print s}' mywords.txt)awk -v wordlength=7 'length($1) == wordlength {s+=$2}END{print s}' mywords.txt
149471023
awk -v wordlength=7 'length($1) == wordlength {sum += $2; print $1, $2, sum} END {print sum}' mywords.txt | tail
zygomas 4 149470398
zygosis 3 149470401
zygotes 181 149470582
zygotic 177 149470759
zymogen 135 149470894
zymosan 12 149470906
zymotic 13 149470919
zymurgy 21 149470940
zyzzyva 83 149471023
149471023
Now that we know that there are 149,471,023 7-letter words in all, we can look at something like "zygosis" It occurred three times. Now, how do we use our running sum?
If we were to roll a magic 149,471,023-sided die, and the answer comes up between 149470398 and 149470401 (the running total of the word just before zygosis and the total once the 3 entries of zygosis are counted, then zygosis would be our random word. Assuming a good RNG (Random-Number Generator), the words it guess will occur in the same frequency as words appear in Wikipedia articles.
Note my use of the -v on awk in order to pass a variable in. I like this better than playing yet more bash quoting games, where you double-quoting in, single-quoting in places, and on and on.
This are all of the pieces. All that was left was to figure out which variable names I might want to maintain. Wordlength and the location of the dictionary file were the winners. I tested each section of the pipe in isolation, then, as planned, it all collapsed together.
pickaword() { WORDFREQFILE=/home/mywords.txt;WORDLENGTH=$1; FREQSUM=$(awk -v wordlength="$WORDLENGTH" 'length($1) == wordlength {s+=$2}END{print s}' "$WORDFREQFILE"); CHOICE=$(shuf -i 0-$FREQSUM -n 1); awk -v wordlength="$WORDLENGTH" 'length($1) == wordlength {sum += $2; print $1, $2, sum} END {print sum}' "$WORDFREQFILE" | awk -v threshold="$CHOICE" '$3 < threshold' | tail -2 | head -1 | cut -f1 -d' '; }I stuck that function in my .bashrc file and I'm good.
Anything left to do? Not really, but if I were feeling anal I'd ditch the dependency on the dictionary file. I want things that are completely portable.
How could I do that? Probably using a HEREDOC. But right now that feels like serious overkill. Maybe if somebody else wanted to use it, I would. I'd also be interested to see if it was necessary to chop off some of the longtail words. Meh.
It was a fun little evening project that I didn't even work too hard at. Next up. Wordle, only with 9-letter words in 3-dimensions! (Just kidding!)




Comments ()